LLM(Large Language Model) is a kind of Deep Learning Model which possess the ability to understand, interpret, and generate human like text. Large in this context denotes both the amount of paramters and data involved.
LLMs are trained to perform a task called Next Word Prediction. Though it seems to be a very simple problem, solving this also helps producing solutions for many inherent problems that involves understanding the syntax and semantics of a language.
By employing the use of Transformers, they are able to achieve selective attention to certain parts of inputs that helps in understanding the nuances and enhances prediction.
There are two main stages in building and using an LLM
- Pretraining - Train the model with large data for Next Word Prediction (Also called base or foundation model)
- Finetuning - Use the pretrained model on labelled data for specific tasks
- Instruction Finetuning - The labelled data consists of instruction and answer pairs
- Finetuning for classification - The labelled data consists of texts and their associated labels
The research paper “Attention is all you need” marked the birth of LLMs. Most of the LLMs are transformer based though a very few of them are not. A transformer consists of an encoder and decoder model. They posses a special property called Self-Attention which improves the understanding of the entire sentence in terms of context. The image below illustrates the transformer architecture. 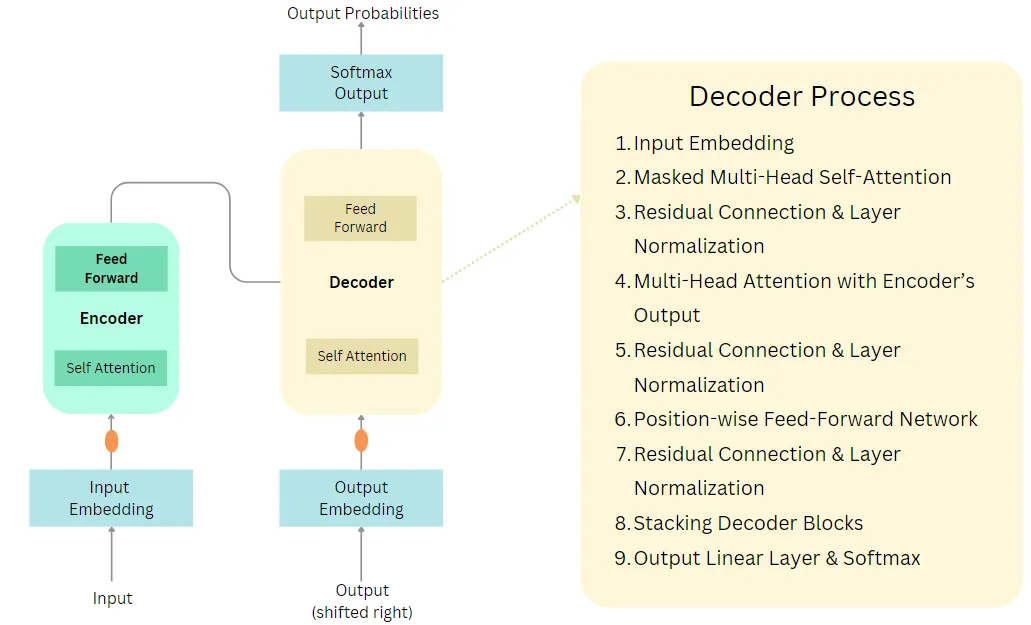{kind=link}
The GPT ( Generative Pretrained Transformer ) models are built using the decoder part of the transformer model. The following image explains the architecture of a GPT.
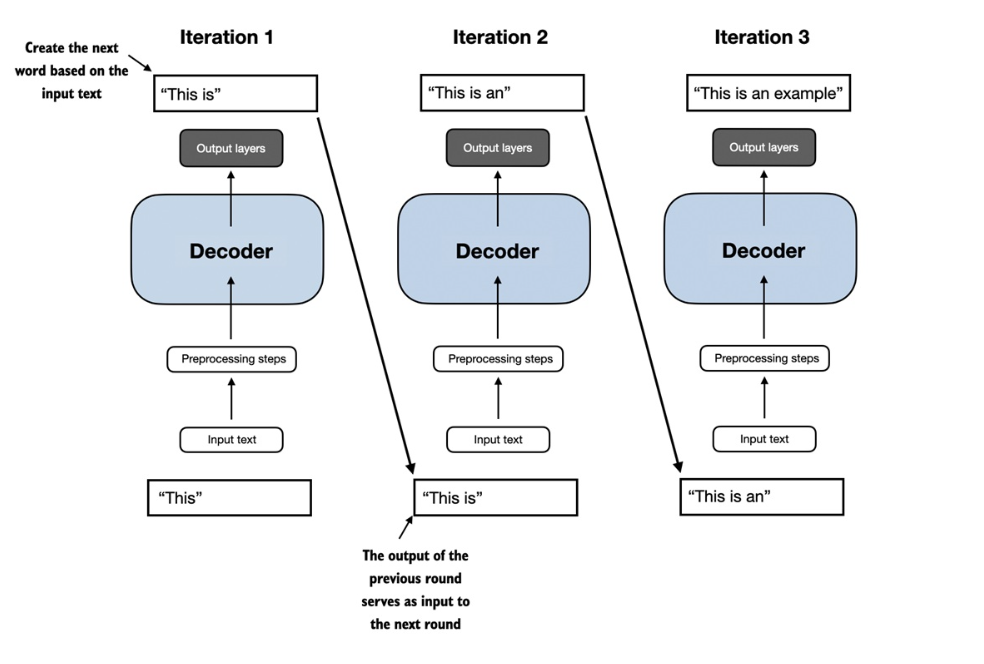
Though the initial objective of GPT was to perform next word prediction, it was also observed that they were good at translation tasks. The ability to perform tasks that the model wasn’t explicitly trained to perform is called an “emergent behaviour”.